Scaling Kubernetes Workloads with Vertical Workload Autoscaler (VWA)
Introduction
Vertical scaling is essential in Kubernetes environments where workloads need to adjust their CPU and memory resources dynamically to meet changing demands. While Horizontal Pod Autoscaling (HPA) manages scaling by adjusting the number of pod replicas, certain workloads—particularly those with stateful configurations or strict resource requirements—benefit more from vertical scaling, which optimizes resource allocation within individual pods.
The Vertical Pod Autoscaler (VPA) is a widely used solution for vertical scaling in Kubernetes, providing recommendations and automatic adjustments of pod resources. However, VPA can introduce disruptions, as it typically requires evicting and restarting pods to apply new resource limits. This can lead to service interruptions and instability, particularly in production environments or applications requiring high availability.
The Vertical Workload Autoscaler (VWA) addresses these challenges by offering a more controlled and configurable approach to applying vertical scaling recommendations. With VWA, resource updates can be managed with greater flexibility, minimizing downtime and disruptions while ensuring workloads run efficiently.
Problem Statement
Kubernetes Vertical Pod Autoscaler (VPA) provides an essential capability for automatically adjusting CPU and memory requests based on actual usage, optimizing resource utilization in dynamic workloads. However, its current implementation poses significant challenges that hinder its broader adoption, particularly in production environments.
Immediate Pod Evictions
The existing VPA Updater and Admission Controller mechanisms apply new resource recommendations by evicting pods immediately. This approach, while necessary for resource adjustment, can cause application downtime or instability, making it unsuitable for critical workloads that require continuous availability.
Lack of Fine-Grained Control
VPA’s built-in functionality does not offer flexibility in managing the timing, frequency, or magnitude of resource adjustments. Users cannot configure precise update intervals or gradual changes (step size), limiting their control over how and when adjustments are made, especially in environments with strict performance or operational constraints.
Conflicts with Horizontal Pod Autoscaler (HPA) and KEDA
VPA operates independently of Horizontal Pod Autoscaler (HPA) and KEDA, both of which are commonly used to scale pods based on CPU and memory metrics. This independence often leads to conflicts in scaling decisions between the autoscalers, resulting in inefficient resource management and potential performance degradation.
Limitations with StatefulSets and DaemonSets
VPA’s methodology for applying resource updates can disrupt the scaling and management requirements of StatefulSets and DaemonSets. These types of workloads have unique characteristics, such as ordered restarts and strict identity preservation, which do not align well with VPA’s eviction-based updates.
Overall, while VPA offers substantial benefits for resource optimization, these limitations in its current form restrict its applicability in production environments where workload stability, fine-grained control, and seamless integration with other autoscaling tools are critical.
VPA Overview
The Kubernetes Vertical Pod Autoscaler (VPA) helps optimize resource allocation by automatically adjusting CPU and memory requests for pods based on historical and real-time usage. It improves efficiency by preventing over-provisioning and ensuring workloads have the right amount of resources at any given time. VPA consists of the following core components:
VPA Recommender
The Recommender monitors and analyzes resource usage patterns over time and generates optimal resource requests (CPU and memory) for containers.
- Function: Continuously updates resource recommendations based on collected metrics.
VPA Updater
The Updater applies the Recommender’s suggestions by recreating pods with the updated resource requests, ensuring pods have the correct resources over time.
- Function: Evicts and recreates pods to apply updated resource settings.
VPA Admission Controller
The Admission Controller modifies the resource requests of new pods based on VPA recommendations at the time of pod creation.
- Function: Automatically adjusts resource settings during pod creation.
Installing VPA Recommender Only
To install just the VPA Recommender without the Updater or Admission Controller, use the Fairwinds Helm Chart:
helm install vpa fairwinds-stable/vpa --version 4.6.0 --set "recommender.enabled=true,updater.enabled=false,admissionController.enabled=false,metrics-server.enabled=true,recommender.image.tag=1.2.1" --namespace vpa --create-namespace
Tuning VPA Recommender Parameters
When configuring the VPA Recommender, consider these key parameters for adjusting recommendation behavior:
-
Recommendation Margin: Adds a buffer to recommended resources.
recommender: recommendationMarginFraction: 0.2 # default: 0.15 -
Resource Limits: Sets minimum and maximum allowed resource requests.
recommender: minAllowed: cpu: 50m memory: 100Mi maxAllowed: cpu: 1 memory: 1Gi -
Update Frequency: Controls how often recommendations are updated.
recommender: updateInterval: 5m # default: 1m
By adjusting these parameters, you can fine-tune the VPA Recommender to align with your workload characteristics and cluster performance needs.
Vertical Workload Autoscaler (VWA): A Flexible and Controlled Approach
The Vertical Workload Autoscaler (VWA) enhances the functionality of the Vertical Pod Autoscaler (VPA) by providing a more flexible and controlled method for applying resource recommendations. This makes VWA a safer and more configurable alternative to the standard VPA Updater and Admission Controller.
Overview
VWA builds upon the VPA framework, relying on the VPA Recommender component to generate resource recommendations essential for effective vertical scaling. While VPA determines the appropriate resource allocations, VWA introduces significant improvements by allowing these recommendations to be applied in a controlled manner, thus respecting the workload’s defined update strategies and disruption budgets. VWA effectively replaces the VPA Updater and VPA Admission Controller, offering a unified solution for managing vertical scaling in Kubernetes environments.
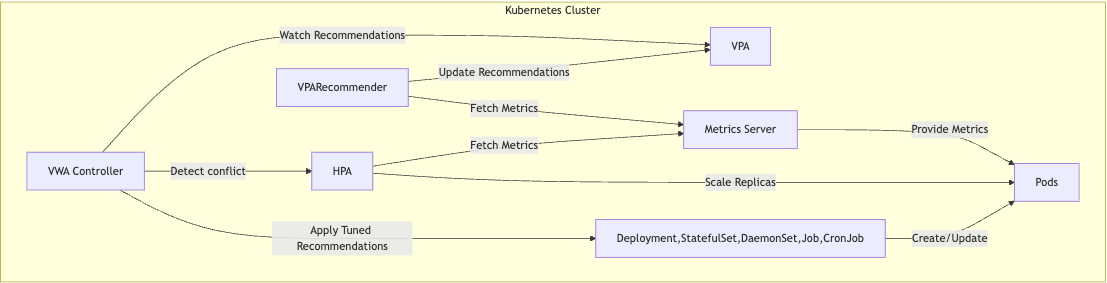
Key Features
- Gradual, Non-Disruptive Scaling: VWA respects PodDisruptionBudgets (PDB) and existing deployment strategies for Deployment, StatefulSet, DaemonSet, Jobs, and CronJobs objects. By adhering to these configurations, VWA allows for resource updates to be applied in a controlled manner, reducing potential disturbances and minimizing downtime during the scaling process.
- Custom Update Intervals: VWA provides multiple mechanisms for controlling when resource recommendations are applied. Users can set the frequency of resource evaluations and updates, allowing for precise timing in production environments. Additionally, the update tolerance feature allows for small adjustments to be ignored, preventing unnecessary disruptions. The allowed update windows specify the periods during which resource changes can occur, ensuring that updates are applied at the most opportune times. Together, these controls help minimize the impact of resource changes on running applications while maximizing performance and availability.
- Seamless HPA/KEDA Integration: VWA detects and handles conflicts with Horizontal Pod Autoscalers (HPA) or KEDA by disabling conflicting vertical scaling metrics, ensuring vertical and horizontal autoscaling can work together harmoniously.
- QoS Class Control: VWA allows fine-tuning of resource requests and limits during vertical scaling to ensure that pods maintain the desired Quality of Service (QoS) class (e.g.,
Burstable,Guaranteed) when applying VPA recommendations. - GitOps Compatibility: VWA leverages custom annotations to facilitate integration with GitOps tools like ArgoCD. These annotations can be used to establish agreed-upon configurations that allow GitOps tools to ignore resource changes for managed objects. This approach helps prevent update conflicts, ensuring that VWA can apply necessary adjustments while maintaining the desired state defined by GitOps practices.
Addressing VPA Limitations
-
Controlled Resource Updates: VWA enhances the resource update process by eliminating the need for immediate pod evictions, as seen in the VPA Updater. Instead, it provides granular control over updates through configurable options such as tolerance for minor adjustments and allowed update windows. This flexibility ensures that resource changes are applied in a less disruptive manner, improving overall application stability.
-
HPA Conflict Avoidance: VWA effectively detects and handles conflicts with Horizontal Pod Autoscalers (HPA) by intelligently managing the application of resource recommendations. It can prioritize certain metrics based on the workload’s requirements, ensuring that vertical scaling complements horizontal scaling without introducing contention.
-
Granular Update Control: Users have the ability to configure resource updates not just at a global level but also at the individual workload instance level. This allows for tailored adjustments that meet the specific needs of different applications, providing greater operational flexibility.
-
Broader Workload Support: VWA supports a wider range of workload types, including StatefulSet and DaemonSet, which necessitate more sophisticated scaling strategies compared to typical horizontal scaling solutions. This broad support ensures that VWA can effectively manage diverse workloads within a Kubernetes environment.
-
Simplified Installation and Configuration: VWA is designed for ease of use, featuring streamlined installation and configuration processes. This simplification helps users quickly deploy and manage the autoscaler without extensive setup, allowing teams to focus on delivering value rather than managing infrastructure complexities.
Harmonizing with HPA and KEDA
VWA’s ability to detect HPA or KEDA usage ensures that vertical scaling complements horizontal scaling. For example, if HPA (or KEDA) scales based on CPU metrics, VWA can ignore CPU recommendations, focusing on memory adjustments instead. This prevents conflicts and ensures both scaling methods operate smoothly.
This comprehensive approach ensures that VWA provides a safer and more flexible vertical scaling solution while maintaining the availability and performance of workloads in diverse Kubernetes environments.
Vertical Workload Autoscaler CRD
VerticalWorkloadAutoscaler CRD Example
apiVersion: autoscaling.workload.io/v1alpha1
kind: VerticalWorkloadAutoscaler
metadata:
name: example-vwa
spec:
vpaReference:
name: example-vpa
allowedUpdateWindows:
- dayOfWeek: Monday
startTime: "01:00"
endTime: "05:00"
timeZone: "UTC"
avoidCPULimit: true
ignoreCPURecommendations: false
ignoreMemoryRecommendations: false
qualityOfService: Guaranteed
updateFrequency: "5m"
updateTolerance:
cpu: 10
memory: 10
customAnnotations:
example-annotation: "true"
status:
conditions:
- lastTransitionTime: "2024-10-01T12:34:56Z"
message: "Successfully updated resource requests"
observedGeneration: 1
reason: ResourceUpdateSuccessful
status: "True"
type: UpdateSucceeded
conflicts:
- conflictWith: HPA
resource: example-hpa
reason: "Conflict with CPU scaling metrics"
lastUpdated: "2024-10-01T12:34:56Z"
recommendedRequests:
container-name:
requests:
cpu: "500m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "512Mi"
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-deployment
Explanation of Fields
vpaReference: A reference to theVerticalPodAutoscalerthat the VWA is managing.allowedUpdateWindows: Specifies time windows during which updates to resource requests are allowed. Includes day of the week, start time, end time, and time zone.avoidCPULimit: A boolean to avoid setting CPU limits on the managed resource. Default istrue.ignoreCPURecommendations: Iftrue, the VWA will not adjust resource requests or limits based on CPU metrics. Default isfalse.ignoreMemoryRecommendations: Iftrue, the VWA will not adjust resource requests or limits based on memory metrics. Default isfalse.qualityOfService: Defines the QoS class to apply to the managed resource, eitherGuaranteedorBurstable. Default isGuaranteed.updateFrequency: Frequency at which the VWA checks and applies updates to resource requests. Default is5m.updateTolerance: Defines tolerance thresholds for CPU and memory updates as a percentage. Default values are 10% for both.customAnnotations: A map of annotations that will be applied to the target object.
Status Fields
conditions: Provides detailed information about the current operational state, including timestamps, reason, and status.conflicts: A list of resources that conflict with VWA’s recommendations, such as conflicting with HPA scaling metrics.lastUpdated: Timestamp of the last update.recommendedRequests: Recommended CPU and memory requests for the managed resource.scaleTargetRef: A reference to the resource (e.g.,Deployment,StatefulSet,DaemonSet) that the VWA is managing.
Comparison with VPA Updater and Admission Controller
While the VPA Updater and Admission Controller are core components of the Vertical Pod Autoscaler (VPA) system, they have certain limitations that can impact production workloads, especially in environments where minimizing disruption and gaining granular control over scaling decisions are important. The VerticalWorkloadAutoscaler (VWA) controller addresses many of these concerns while offering a more flexible and safer approach to vertical scaling.
VPA Updater
The VPA Updater works by monitoring running pods and determining when they need resource adjustments, based on recommendations from the VPA Recommender. When updates are necessary, it evicts pods to allow new pods to be recreated with updated resource requests and limits. While this process is efficient for applying recommendations, it has some downsides:
-
Pod Evictions: The VPA Updater immediately evicts pods that need resizing, which can cause service interruptions. While it respects Pod Disruption Budgets (PDBs), it may still lead to increased pod churn, particularly in auto-scaling environments or high-availability services. Additionally, the VPA Updater is unaware of the deployment strategy configuration (such as RollingUpdate or Recreate). This lack of awareness can interfere with carefully configured deployment strategies, potentially causing disruptions that break the intended process flow and destabilize running services.
-
Disruption to Applications: In scenarios where many pods need to be updated at once, the forced evictions can result in temporary inconsistencies in application behavior or performance, especially in critical or stateful services.
VPA Admission Controller
The VPA Admission Controller handles resource recommendations at the time of pod creation. It works as a Mutating Admission Webhook, intercepting pod creation requests and injecting recommended resource values (requests and limits) before the pod is scheduled. However, this approach has its own set of challenges:
-
No Effect on Existing Pods: The Admission Controller only modifies pods during their creation or restart, meaning existing pods are not updated unless they are explicitly recreated, which limits its ability to immediately optimize running workloads.
-
Operational Complexity: Proper configuration and certificate management are required for the Admission Controller to function securely, adding to the operational overhead.
-
Latency: The mutation of pod specifications can introduce some latency in the pod creation process, potentially delaying the deployment of critical workloads.
VWA Controller: A Safer and More Flexible Alternative
The VerticalWorkloadAutoscaler (VWA) offers an alternative that addresses many of the operational challenges presented by both the VPA Updater and Admission Controller, while still achieving the same goal of optimizing pod resource utilization.
-
Controlled Resource Updates: Unlike the VPA Updater, which immediately evicts pods for resizing, the VWA controller provides more control by applying resource updates according to a configurable schedule, minimizing disruption. You can define update windows, update frequency, and thresholds (like tolerance levels) to determine when updates should be applied. This makes the process more predictable and less disruptive, especially in production environments.
-
Gradual Scaling: VWA allows for more gradual scaling. Instead of immediately applying all recommendations, it can make smaller, incremental changes based on user-defined thresholds. This reduces the risk of performance hiccups and enables smoother transitions to new resource configurations.
-
Fewer Pod Evictions: The VWA controller avoids unnecessary evictions by updating resource configurations without forcing immediate pod restarts. In contrast to the VPA Updater’s aggressive eviction policy, VWA lets you control when updates should take place, lowering the risk of application downtime.
-
Better Fit for Stateful or Critical Workloads: StatefulSets and other critical workloads that require careful handling of restarts can benefit from VWA’s more conservative approach. The ability to configure when and how updates happen helps ensure that performance is maintained even when resource recommendations change.
-
Customizable Tolerance: VWA allows you to set tolerance levels for CPU and memory recommendations, meaning small or insignificant changes can be ignored, reducing unnecessary updates and further enhancing stability.
Considerations for Implementation
The VerticalWorkloadAutoscaler (VWA) controller provides notable advantages in vertical scaling, particularly for production environments that require minimal disruption. While the VPA solution remains effective for many scenarios—especially where frequent pod evictions are acceptable or in non-production workloads—the VPA’s straightforward design and seamless integration with Kubernetes continue to make it a useful resource management tool.
The VWA addresses specific limitations associated with the VPA Updater and Admission Controller, offering enhanced control and flexibility. This makes it particularly beneficial in complex, high-availability, or stateful environments where managing resource allocation is critical. As with any tool, assessing the specific needs of the workload and environment will guide the decision to implement the VWA or stick with the VPA.
Examples
Deployment Example
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
spec:
replicas: 3
template:
metadata:
labels:
app: web-app
spec:
containers:
- name: web
image: nginx
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: web-app-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
updatePolicy:
updateMode: "Off"
---
apiVersion: autoscaling.workload.io/v1alpha1
kind: VerticalWorkloadAutoscaler
metadata:
name: web-app-vwa
spec:
vpaReference:
name: web-app-vpa
avoidCPULimit: true
updateFrequency: 5m
updateTolerance:
cpu: 10
memory: 15
StatefulSet Example (Redis Cluster)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster
spec:
replicas: 3
serviceName: redis-cluster
template:
spec:
containers:
- name: redis
image: redis:6.2
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: redis-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: StatefulSet
name: redis-cluster
updatePolicy:
updateMode: "Off"
---
apiVersion: autoscaling.workload.io/v1alpha1
kind: VerticalWorkloadAutoscaler
metadata:
name: redis-vwa
spec:
vpaReference:
name: redis-vpa
updateFrequency: 10m
qualityOfService: Burstable
updateTolerance:
cpu: 15
memory: 20
Disclaimer: JVM Applications
The Vertical Workload Autoscaler (VWA), like the VPA, is not recommended for use with containerized Java (JVM) applications. JVM-specific behaviors, such as unpredictable garbage collection cycles and complex memory management (e.g., heap vs. non-heap memory), lead to resource recommendations that may not align with actual application needs. These challenges can result in inefficient scaling and potential over-provisioning.
For JVM applications, it’s often more effective to rely on manual resource tuning or custom autoscaling solutions tailored to JVM metrics and behaviors.
Conclusion
The VerticalWorkloadAutoscaler (VWA) controller offers a practical solution for managing vertical scaling in Kubernetes environments. With its focus on providing more control and reducing disruptions, VWA is designed to support both critical applications and stateful workloads effectively. It aims to make resource optimization a smoother process while respecting production requirements.
Feedback is always welcome, and thoughts or suggestions can be shared through pull requests or issues on the VWA GitHub repository. Contributions from the community are greatly appreciated, as they help to refine and enhance the VWA. Thank you for your interest in improving Kubernetes workload management!